Abstract
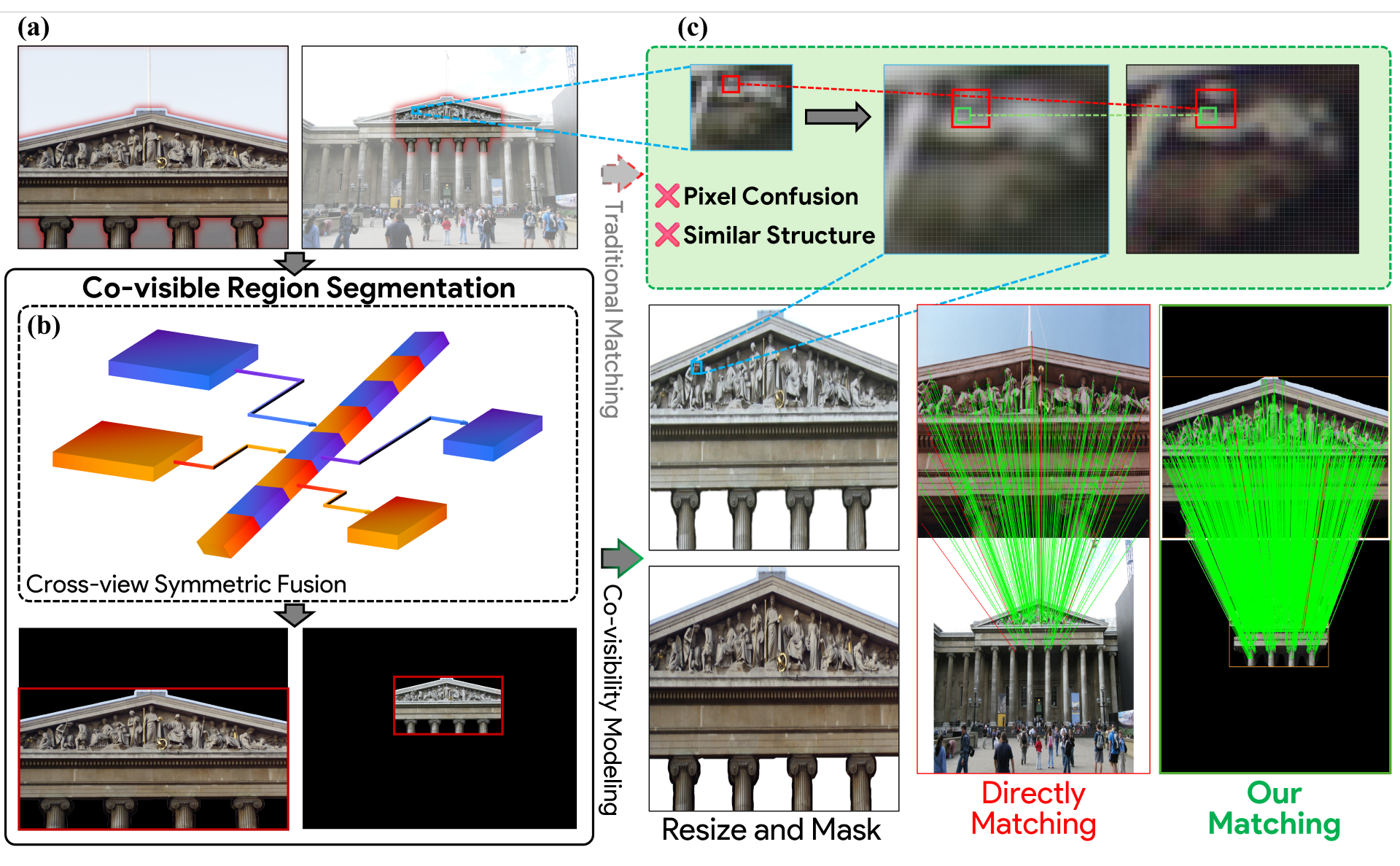
Reliable correspondence estimation is a fundamental problem in image processing, underpinning a wide range of applications such as Structure from Motion, visual localization, and image registration. While recent learning-based approaches have substantially improved the representation capability of local features, most methods still operate primarily at the pixel or patch level. As a result, they lack explicit mechanisms to model regions that are jointly visible across views, leading to brittle behavior when spatial support, semantic context, or visibility patterns vary between images. We propose SAMatcher, a novel feature matching framework that formulates correspondence estimation through explicit co-visibility modeling. Rather than directly establishing point-wise correspondences from local appearance, SAMatcher first predicts consistent co-visible region masks and bounding boxes within a shared cross-view representation space, serving as structured priors to guide and regularize matching. The framework builds upon the Segment Anything Model (SAM) and introduces a symmetric cross-view interaction mechanism that treats paired images as interacting token sequences, enabling bidirectional semantic alignment and the discovery of jointly supported regions. To jointly optimize region segmentation and geometric localization, we introduce a unified supervision scheme that combines point-sampled mask learning with box regression and mask--box consistency constraints, enforcing cross-view coherence during training. Extensive experiments on challenging benchmarks demonstrate that SAMatcher significantly improves robustness under large-scale geometric and viewpoint variations. These results suggest that monocular visual foundation models can be systematically extended to multi-view correspondence estimation through explicit co-visibility modeling, providing a new perspective on structured representation learning for image matching.
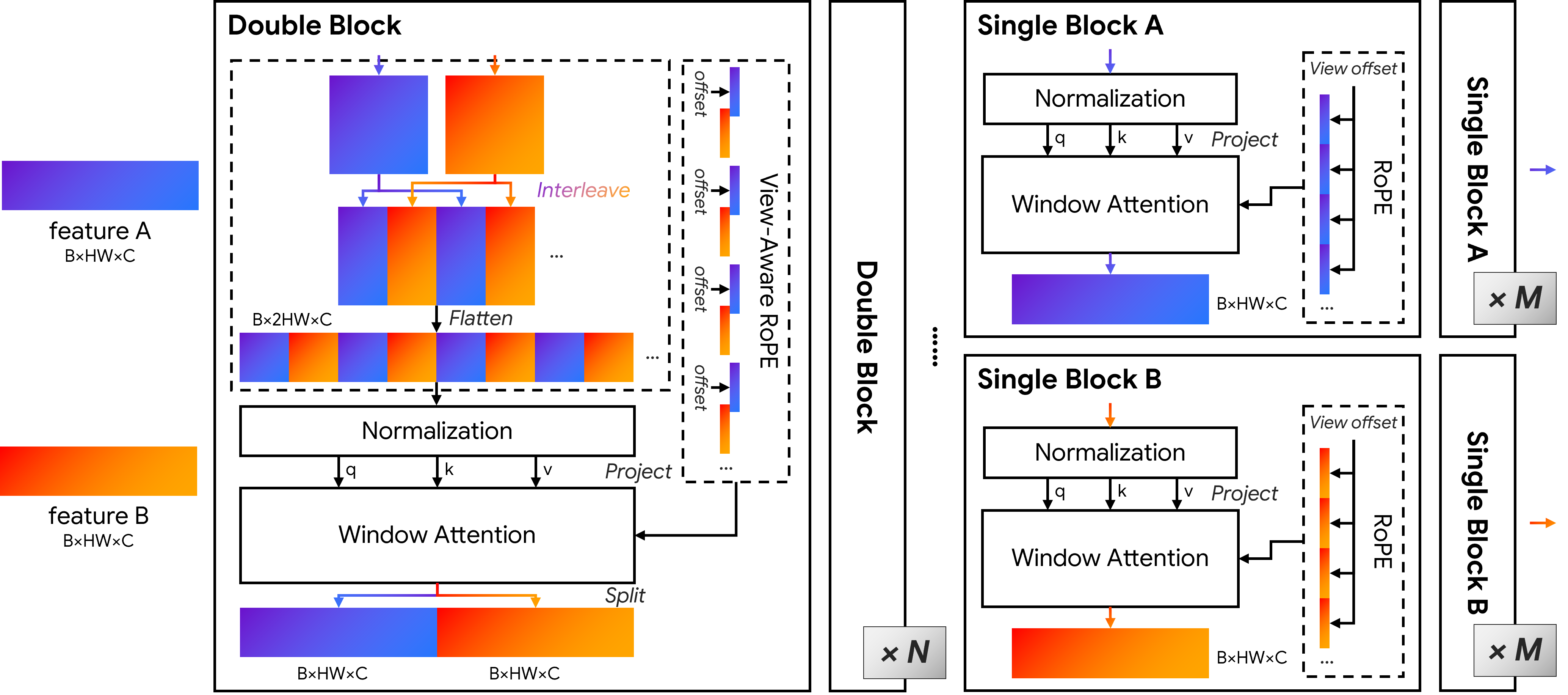
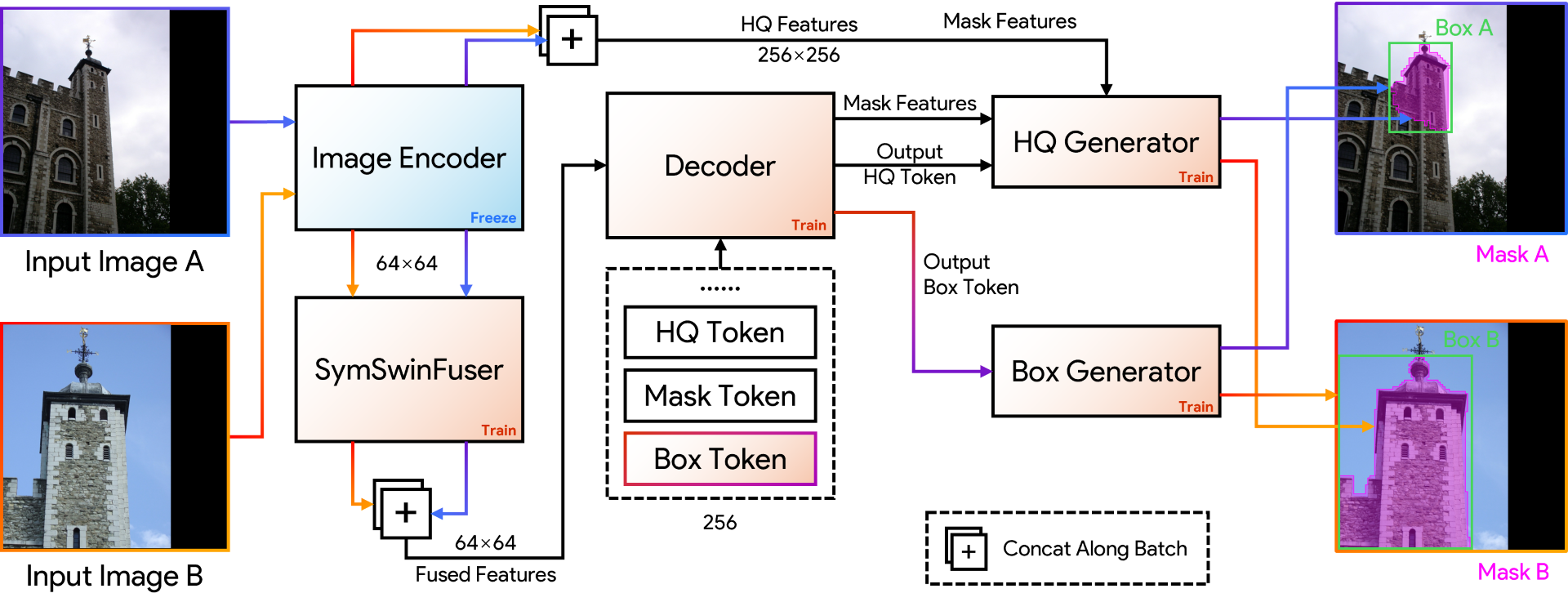
Architecture of the proposed symmetric cross-view feature interaction module. Features from the source and target views are interleaved and processed by a stack of symmetric interaction blocks, enabling bidirectional token-level communication across views. Window-based attention with positional encoding facilitates efficient local interaction while preserving view identity. Subsequent single-view refinement further enhances view-specific structural details, producing cross-view aligned yet discriminative representations for downstream co-visible region prediction and correspondence estimation.
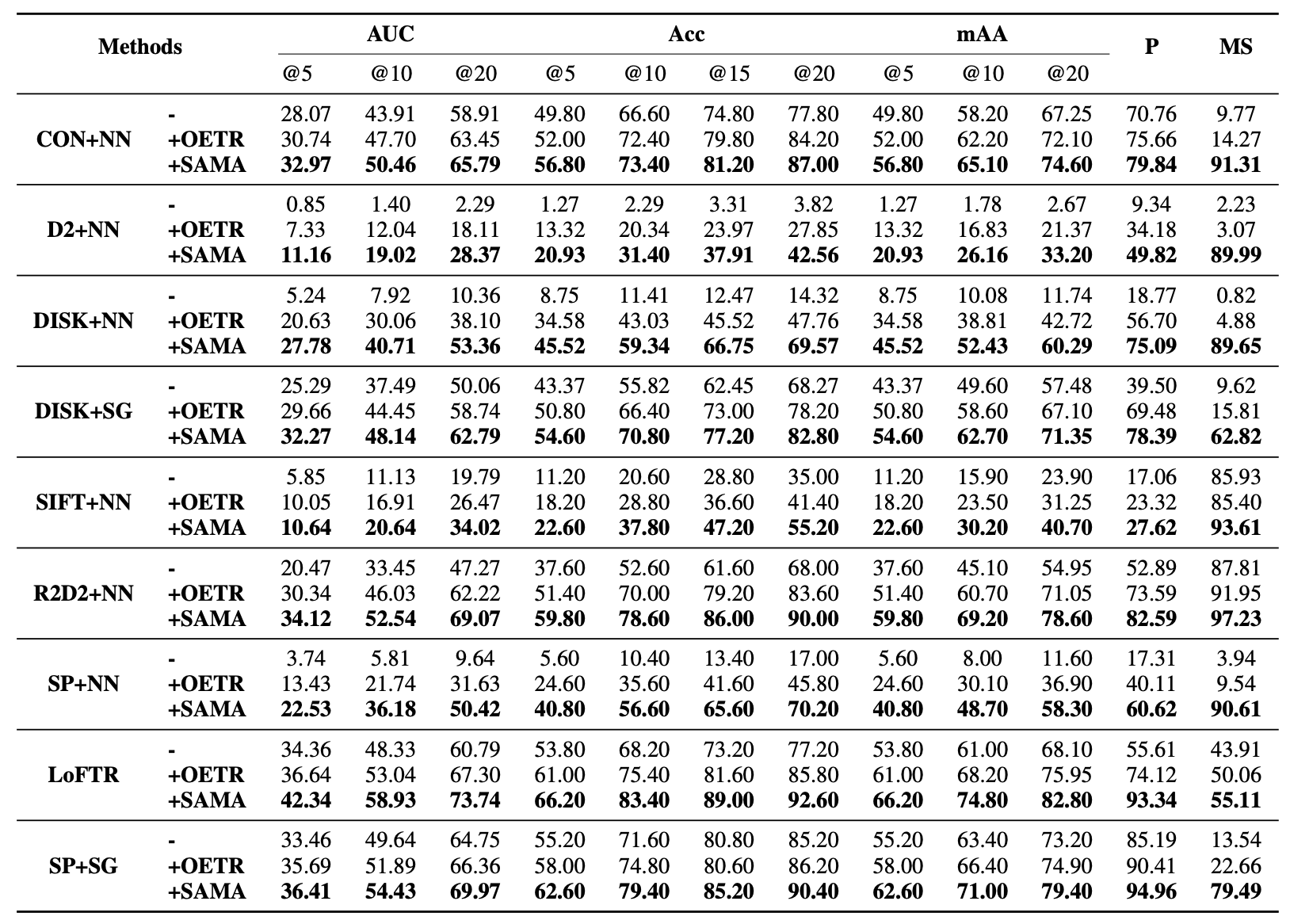
Evaluation on MegaDepth for larger scale differences. Each row corresponds to a complete matching pipeline. Specifically, we consider combinations of feature extractors and matchers, including SuperPoint (SP), DISK, D2-Net (D2), ContextDesc (CON), R2D2, and LoFTR. These are paired with either Nearest Neighbor (NN) or SuperGlue (SG) for matching, except LoFTR, which is an end-to-end dense matching framework.
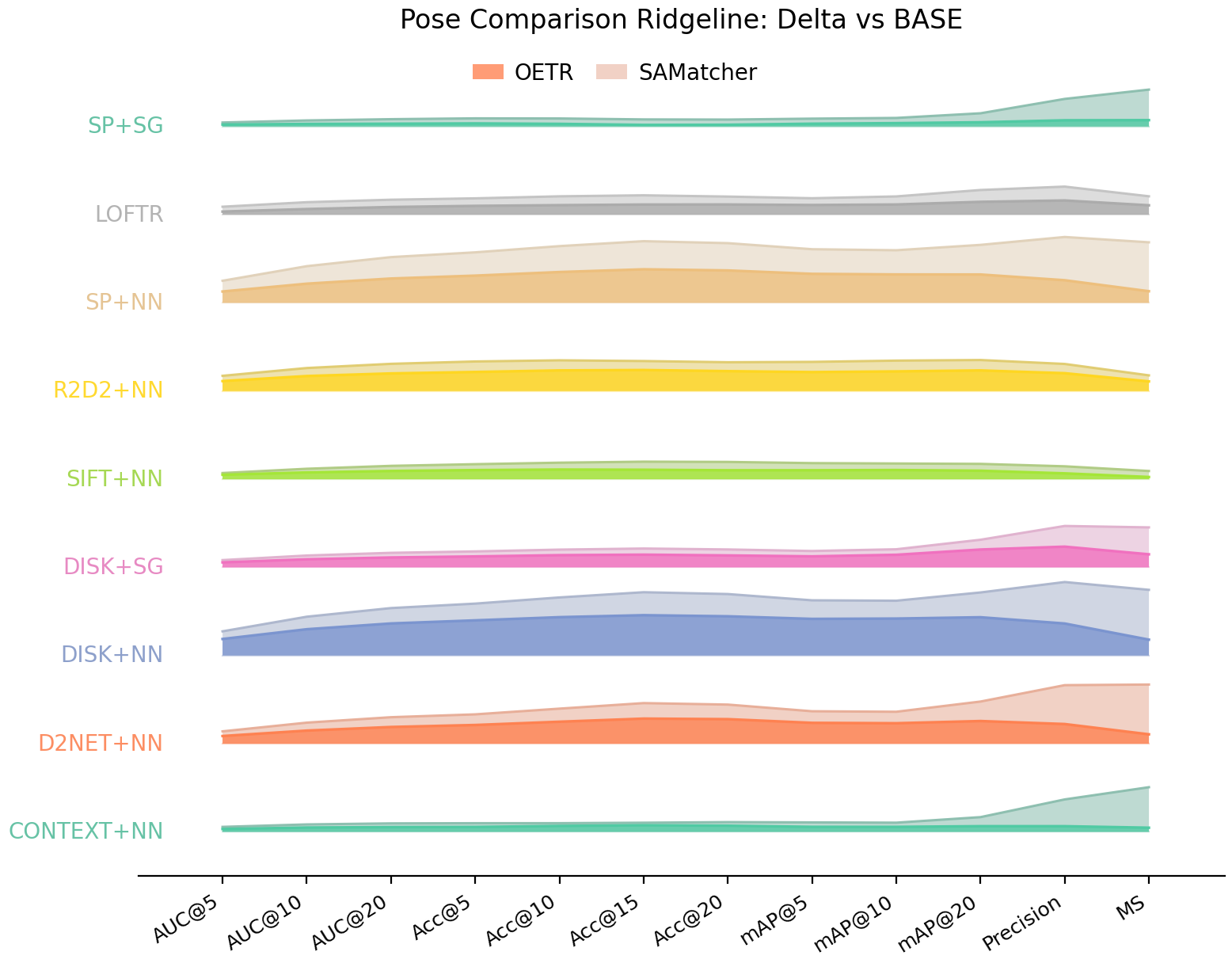
Ridge-style visualization of relative performance gains on MegaDepth. The plot summarizes the improvements brought by OETR (dark shading) and SAMatcher (light shading) over their respective base pipelines across different matching configurations. This visualization highlights the consistency of performance gains across metrics and methods.
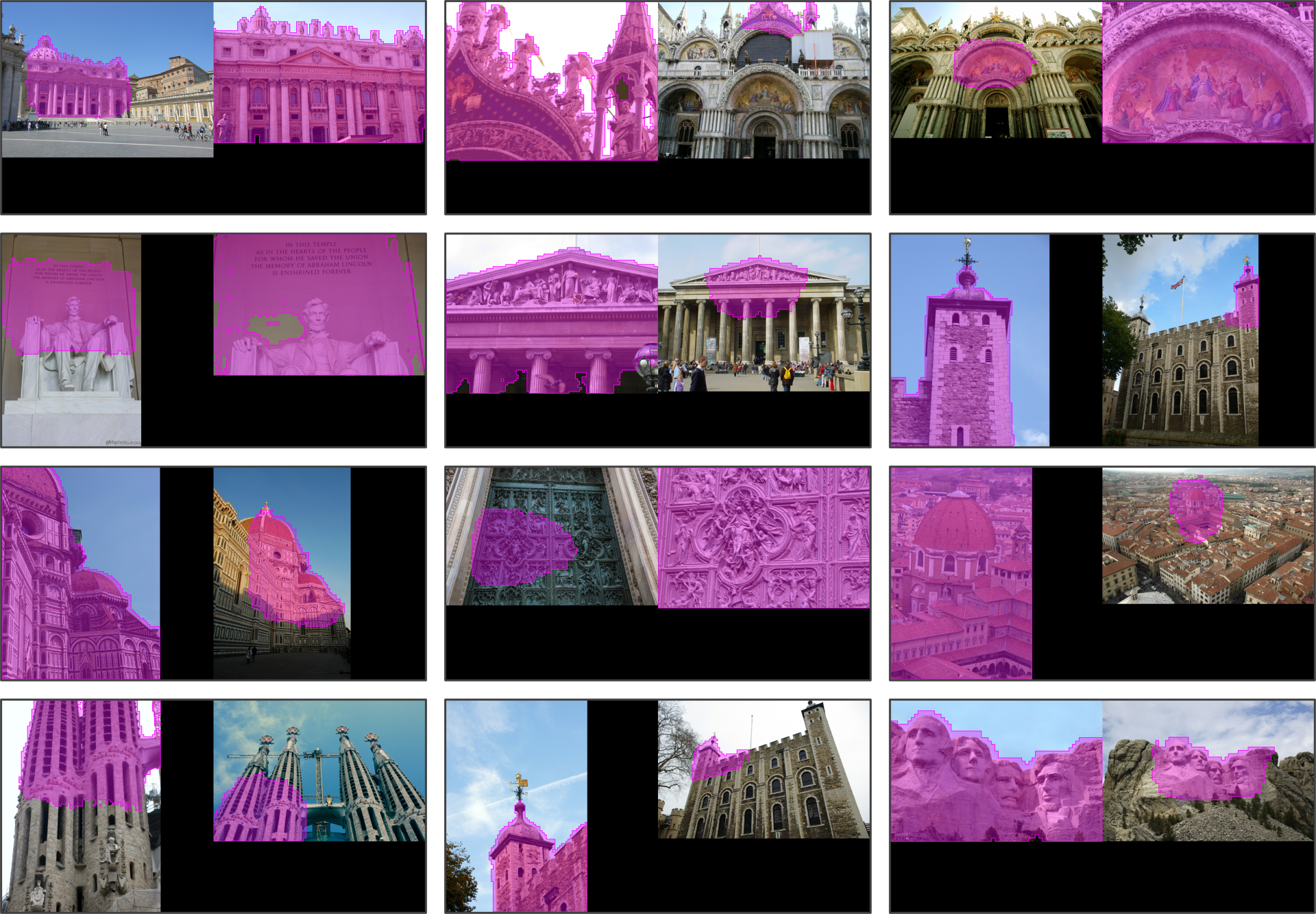
Qualitative comparison of co-visible region detection. For each image pair, we show OETR box-only predictions and SAMatcher mask predictions, with masks overlaid as semi-transparent purple regions. While OETR provides coarse bounding boxes, SAMatcher produces accurate and consistent co-visible regions across views, even under large viewpoint changes and partial overlap.

Region-guided correspondence comparison. SP+SG, +OETR, and +SAMatcher. Green lines denote correct matches, red lines incorrect ones. Under large scale variation, OETR often predicts inaccurate or missing regions, while SAMatcher identifies valid co-visible regions and yields more reliable correspondences.

Complementarity of mask and box predictions. Masks (magenta) provide high recall but coarse coverage, while boxes (red) offer precise localization. Constraining masks with boxes yields refined co-visible regions (green), improving correspondence reliability
