Abstract
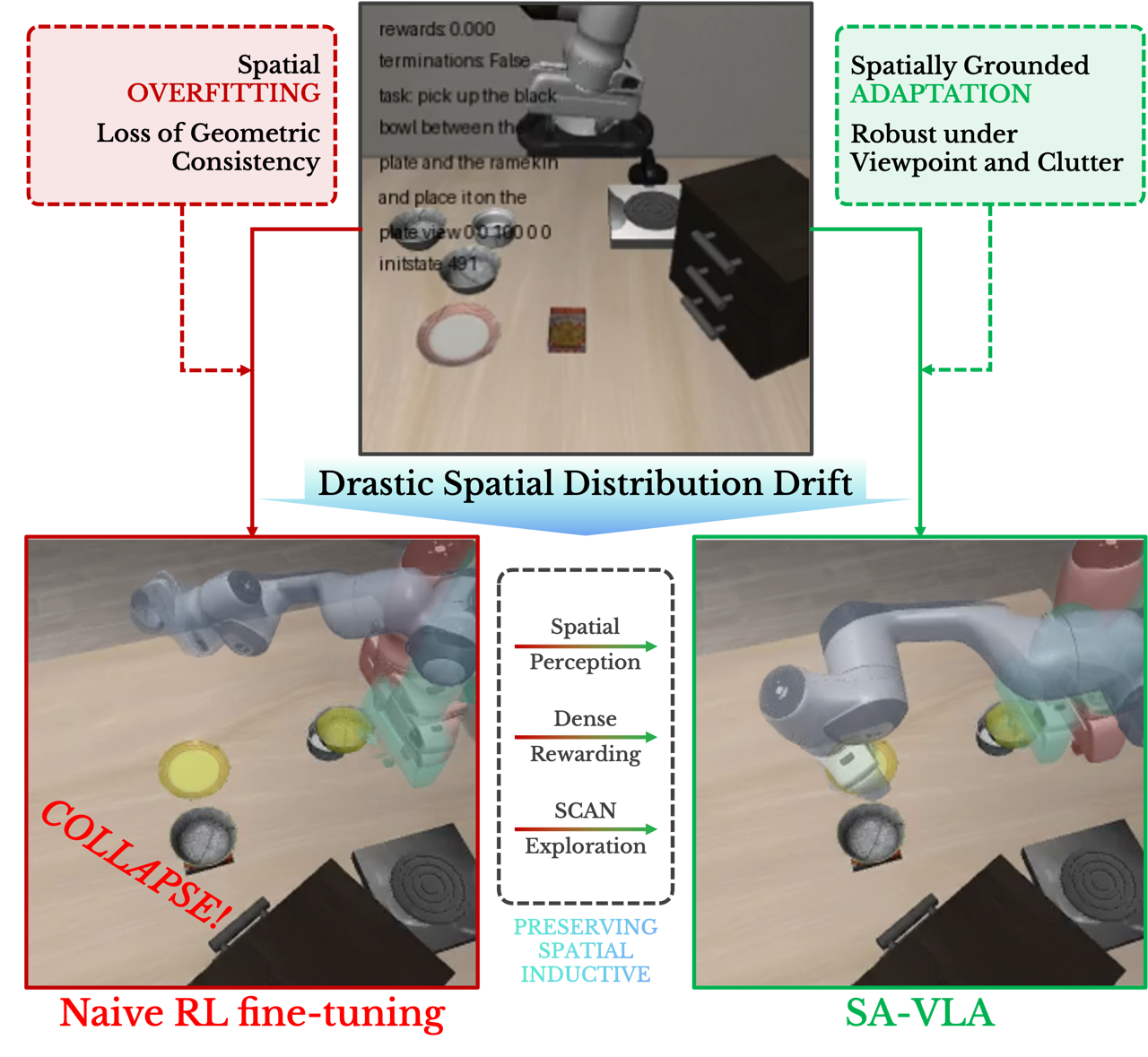
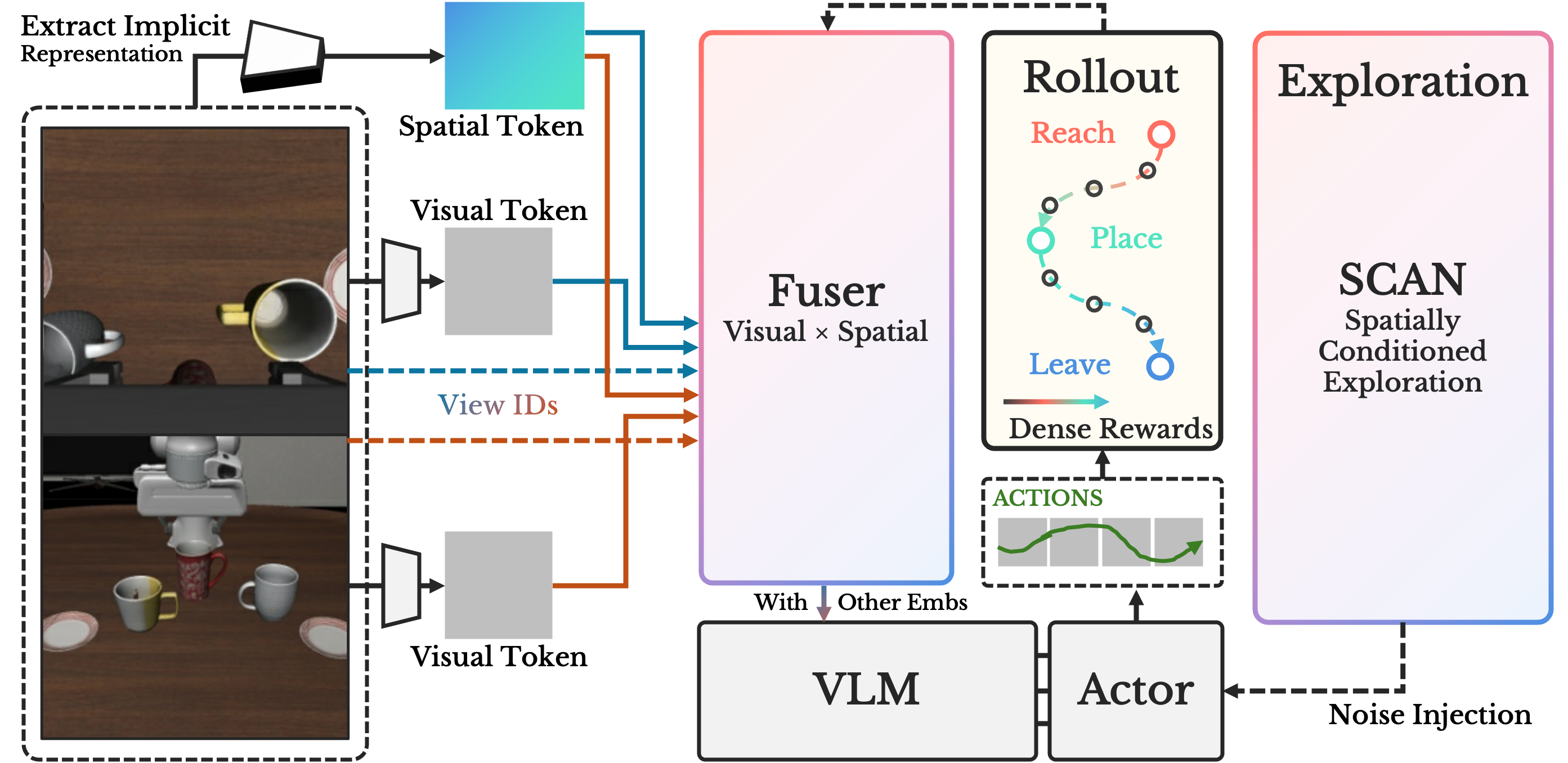
Vision-Language-Action (VLA) models achieve strong performance in robotic manipulation, but reinforcement learning (RL) fine-tuning often degrades generalization under spatial distribution shifts. We analyze flow-matching VLA policies and identify the collapse of spatial inductive bias as a key factor limiting robust transfer. To address this, we propose SA-VLA, which explicitly grounds VLA policies in spatial structure by integrating implicit spatial representations, spatially-aware step-level dense rewards, and SCAN, a spatially-conditioned exploration strategy tailored for flow-matching policies. This principled alignment mitigates policy over-specialization and preserves zero-shot generalization to more complex tasks. Experiments on challenging multi-object and cluttered benchmarks demonstrate that SA-VLA enables stable RL fine-tuning and substantially more robust, transferable behaviors.
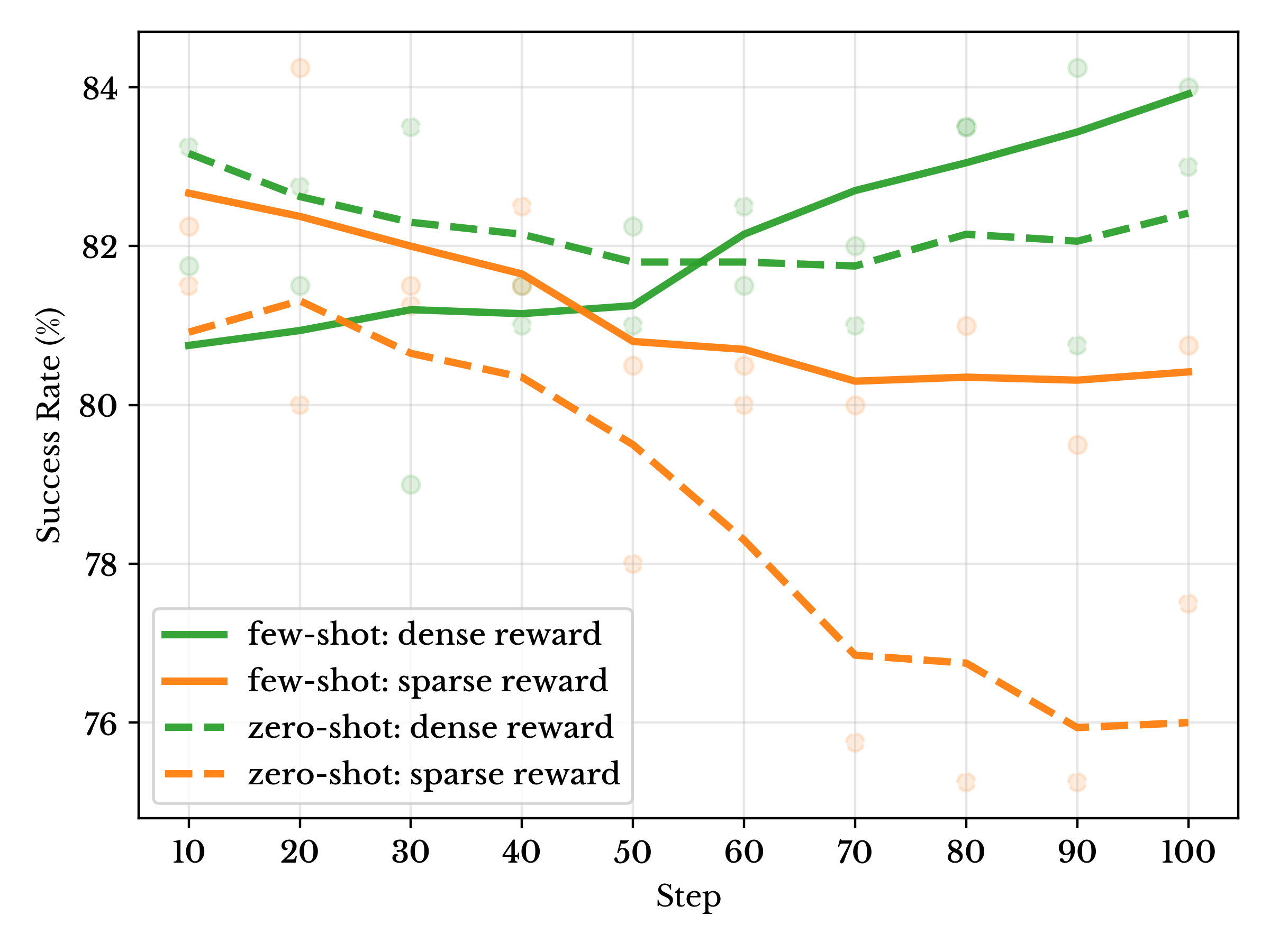
Training dynamics on the LIBERO-PLUS spatial-perturbation subset. Success rates are evaluated using SDE-based policy checkpoints saved every 10 training steps. Solid curves denote few-shot RL, and dashed curves denote zero-shot evaluation.
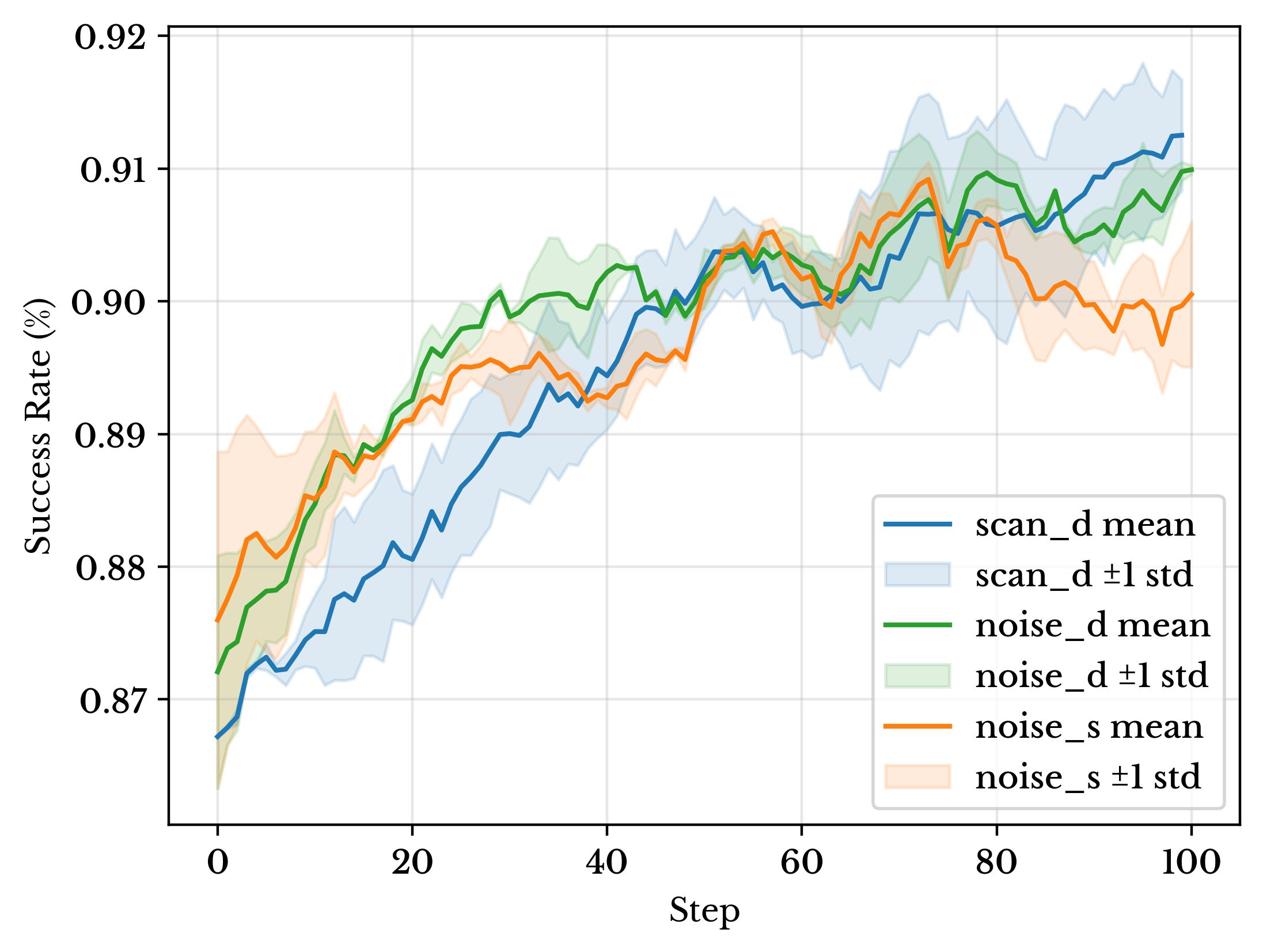
Training dynamics under limited spatial coverage. Dense rewards stabilize RL optimization, while combining dense rewards with SCAN further improves final success rate. Shaded regions denote one standard deviation over two seeds.
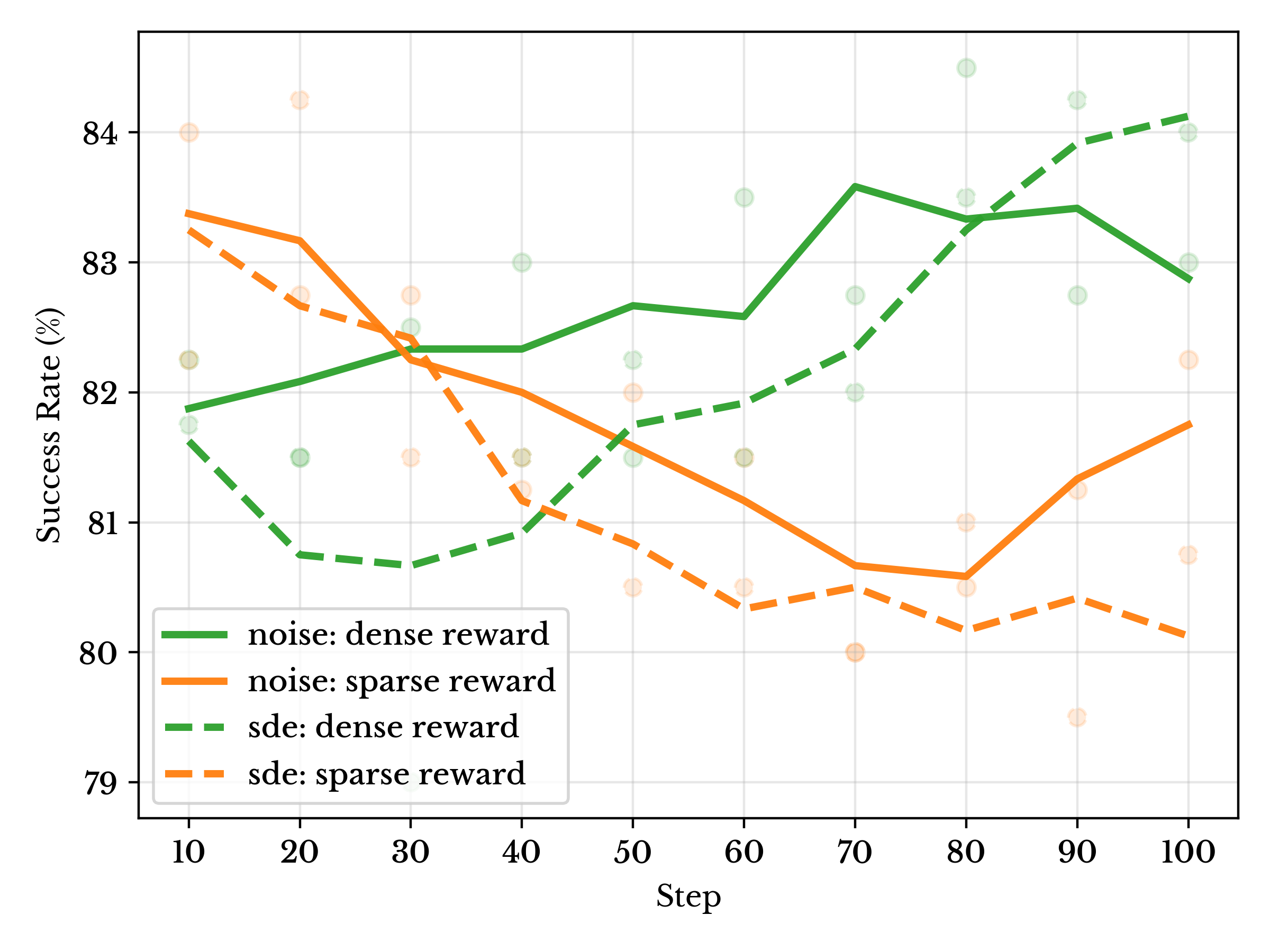
Few-shot evaluation on LIBERO-PLUS comparing SDE-based and learned exploration noise. Across both sparse and dense reward settings, learned noise consistently outperforms SDE-based noise with lower variance and more stable performance.
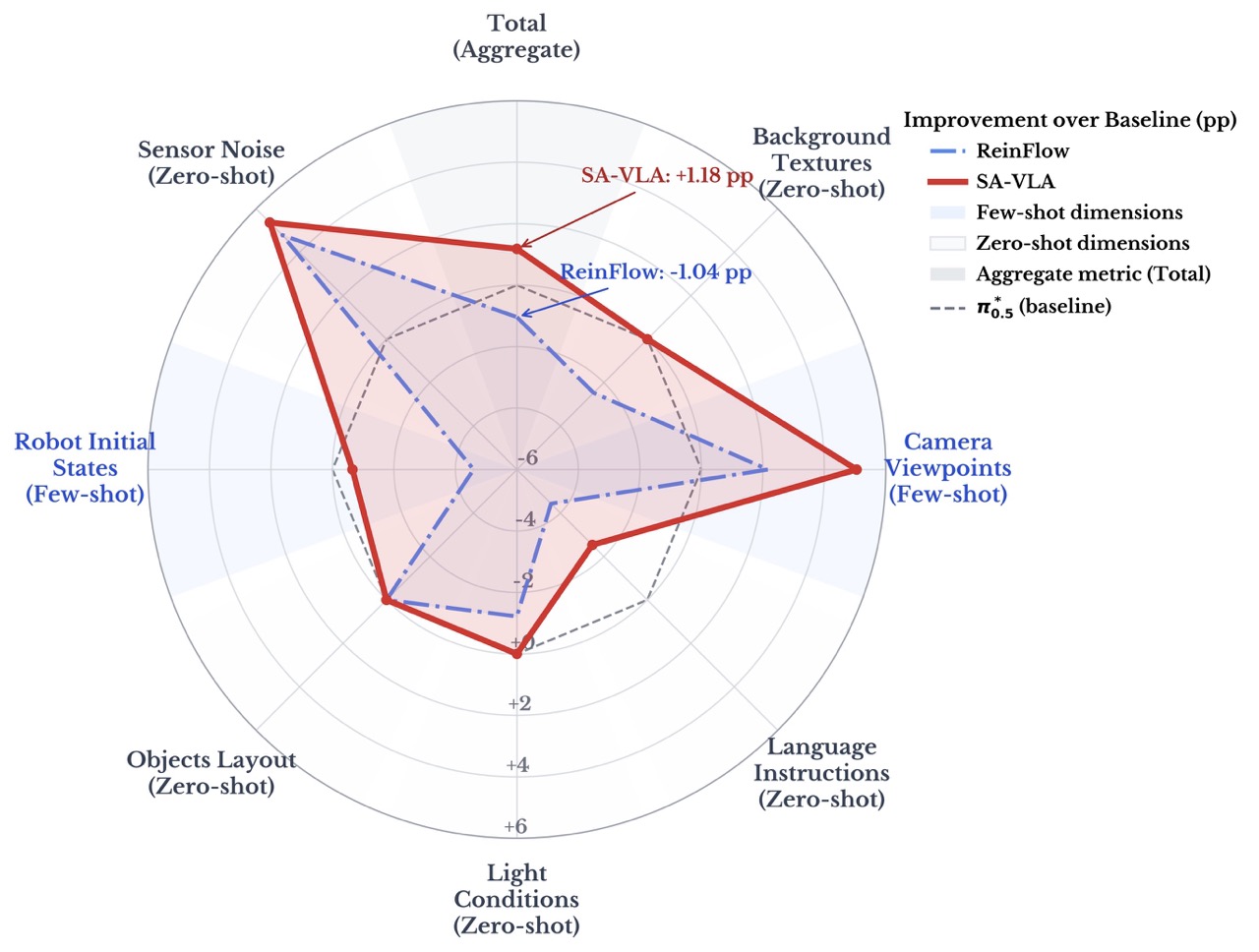
Robustness improvement over π0.5 (pp). CV and RIS are few-shot spatial shifts; others are zero-shot. SA-VLA yields consistent gains with minimal regressions across perturbation types.

Robustness under diverse perturbations. We evaluate π0.5, ReinFlow, and SA-VLA. Results report success rate (mean ± std). CV and RIS are few-shot spatial shifts; others are zero-shot. Total is averaged across all conditions.
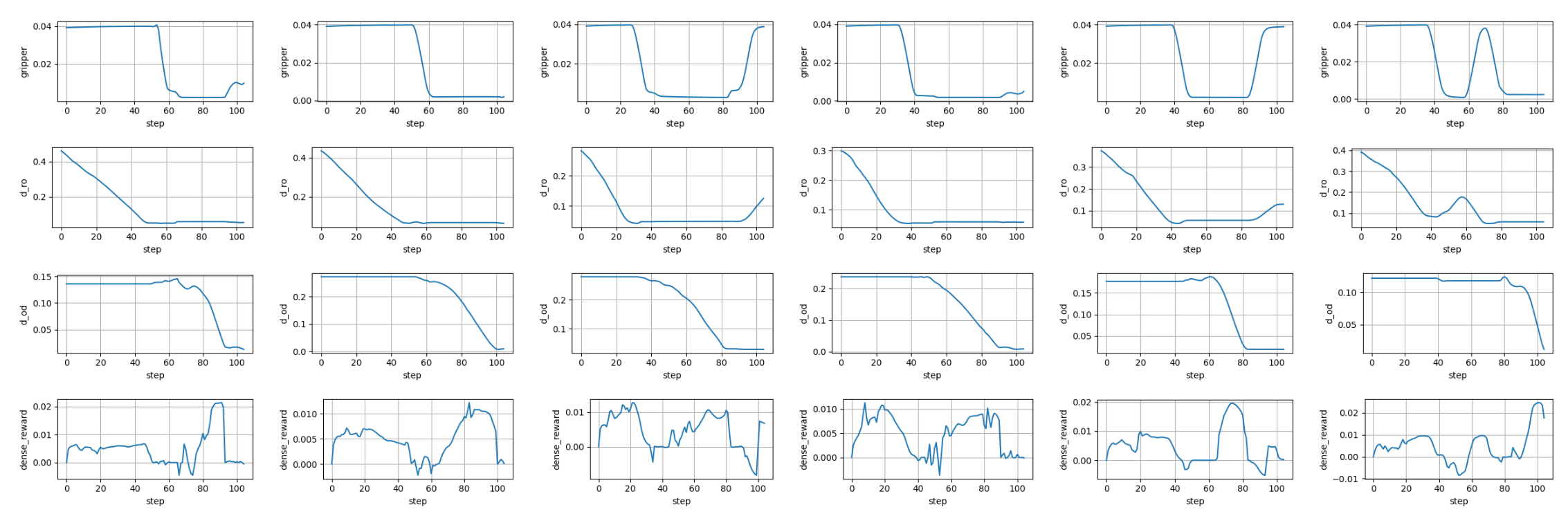
Phase-wise dense reward visualization showing changes in d_ro, d_od, gripper opening angle, and corresponding dense reward throughout task execution.
BibTeX
@inproceedings{pan2026savla,
title={SA-VLA: Spatially-Aware Flow-Matching for Vision-Language-Action Reinforcement Learning},
author={Xu Pan and Zhenglin Wan and Xingrui Yu and Xianwei Zheng and Youkai Ke and Ming Sun and Rui Wang and Ziwei Wang and Ivor Tsang},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
year={2026},
url={https://arxiv.org/abs/2602.00743}
}