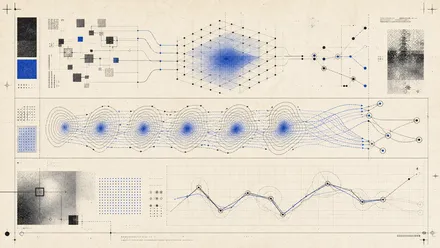
Pi-FS
Temporally coupled latent distributions shorten the flow transport path for few- or single-step action generation within an asynchronous fast–slow policy.
Incoming Research Associate at Nanyang Technological University

Hi, I am Xu Pan, an incoming Research Associate at the Perception and Embodied Intelligence (PINE) Lab, supervised by Prof. Ziwei Wang, within the School of Electrical and Electronic Engineering (EEE), Nanyang Technological University (NTU).
Previously, I received my B.Eng. and M.Sc. degrees from Wuhan University, where I worked at the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing (LIESMARS). I also interned at Baidu, and was a remote research assistant at the Centre for Frontier AI Research (CFAR), Agency for Science, Technology and Research (A*STAR), working closely with Dr. Xingrui Yu.
My research focuses on embodied intelligence, investigating the spatial principles that underpin robust perception, reasoning, and action in the physical world. I develop scalable learning frameworks that enable general-purpose embodied agents to adapt across diverse environments, tasks, and embodiments.
 School of Electrical and Electronic Engineering (EEE),
School of Electrical and Electronic Engineering (EEE), Centre for Frontier AI Research (CFAR),
Centre for Frontier AI Research (CFAR), International Technology R&D Department,
International Technology R&D Department,  Wuhan University
Wuhan UniversityAcknowledgements:
I’m grateful to my collaborators and mentors for their guidance and support, especially
Prof. Ziwei Wang, Dr. Xingrui Yu (A*STAR), Dr. Zimin Xia (EPFL), Dr. Yan Zhang (Baidu), Prof. Hanjiang Xiong (WHU),
and my colleagues/peers including
Zhenglin Wan (NUS), Jiashen Huang (USC), Ziqong Lu (HKU), Qiyuan Ma (WHU), Jintao Zhang (WHU), Chenyu Zhao (WHU), He Chen (WHU),
and others I’ve had the pleasure to work with.
Temporally coupled latent distributions shorten the flow transport path for few- or single-step action generation within an asynchronous fast–slow policy.
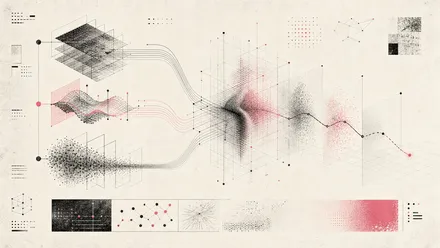
Geometry-aware representation, grounded reward, and annealed exploration for robust flow-matching VLA reinforcement learning.
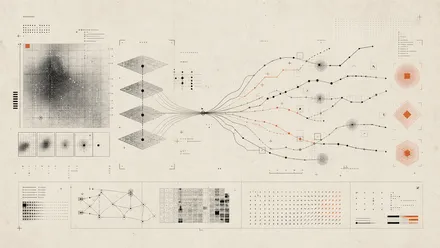
Spatially-aware reinforcement learning for robust flow-matching vision-language-action policies.

Explicit co-visibility modeling with Segment Anything for robust cross-view feature matching.

Scale-aware co-visible region detection for matching images under drastic scale variation.
, Zhenglin Wan, Xingrui Yu*, Xianwei Zheng, Youkai Ke, Ming Sun, Rui Wang, Ziwei Wang, Ivor Tsang
Outstanding Graduating Graduate Student
Wuhan University
Outstanding Graduate Student
Wuhan University
Graduate Academic Excellence Scholarship
Wuhan University
Graduate Academic Excellence Scholarship
Wuhan University
Outstanding Student Leader
Wuhan University
Outstanding Student Club Leader
Wuhan University
Active Contributor to Social Activities
School of Remote Sensing and Information Engineering
Wuhan University Class C Scholarship
Wuhan University
National Second Prize
China Software Cup College Student Software Design Competition
Honorable Mention
Mathematical Contest In Modeling
Third Prize
Asia and Pacific Mathematical Contest in Modeling
First Prize in Hubei Division
China Undergraduate Mathematical Contest in Modeling
Outstanding Student
Wuhan University
Bronze Medal
China Collegiate Algorithm Design & Programming Challenge Contest
Second Prize in Final
Translation & Interpreting Contest of Hubei Province
I follow Stoic philosophy. Life is a joyful ascent: a true mountaineer delights in the climb itself, not just the summit.
Thou sufferest this justly: for thou choosest rather to become good to-morrow than to be good to-day.
I also resonate with the spirit of Slow Science.
We live in an age tyrannized by efficiency, outcomes, and speed, to the point that nothing lasts and nothing leaves a deep impression. In the midst of noisy bubbles and short-lived hype, I hope to take time to think carefully, to doubt, to refine, and to do research that is genuinely meaningful and worth remembering.
